時間剖析
在本章中,我們將提升我們的生命遊戲執行的效能。我們將使用時間剖析來引導我們的努力。
在繼續之前,請先熟悉 Rust 和 WebAssembly 程式碼的時間剖析可用工具。
使用 window.performance.now 函數建立每秒顯示禎次 (FPS) 定時器
這個 FPS 定時器在我們探討如何加速生命遊戲的繪製時會非常有用。
我們從在 wasm-game-of-life/www/index.js 中加入一個 fps 物件開始
const fps = new class {
constructor() {
this.fps = document.getElementById("fps");
this.frames = [];
this.lastFrameTimeStamp = performance.now();
}
render() {
// Convert the delta time since the last frame render into a measure
// of frames per second.
const now = performance.now();
const delta = now - this.lastFrameTimeStamp;
this.lastFrameTimeStamp = now;
const fps = 1 / delta * 1000;
// Save only the latest 100 timings.
this.frames.push(fps);
if (this.frames.length > 100) {
this.frames.shift();
}
// Find the max, min, and mean of our 100 latest timings.
let min = Infinity;
let max = -Infinity;
let sum = 0;
for (let i = 0; i < this.frames.length; i++) {
sum += this.frames[i];
min = Math.min(this.frames[i], min);
max = Math.max(this.frames[i], max);
}
let mean = sum / this.frames.length;
// Render the statistics.
this.fps.textContent = `
Frames per Second:
latest = ${Math.round(fps)}
avg of last 100 = ${Math.round(mean)}
min of last 100 = ${Math.round(min)}
max of last 100 = ${Math.round(max)}
`.trim();
}
};
接著我們在 renderLoop 的每次反覆運算中呼叫 fps 的 render 函數
const renderLoop = () => {
fps.render(); //new
universe.tick();
drawGrid();
drawCells();
animationId = requestAnimationFrame(renderLoop);
};
最後,別忘了在 wasm-game-of-life/www/index.html 中,剛好在 <canvas> 上方加入 fps 元素
<div id="fps"></div>
再加入 CSS 改善它的格式
#fps {
white-space: pre;
font-family: monospace;
}
瞧!重新整理 https://#:8080,現在我們有一個 FPS 計數器了!
使用 console.time 和 console.timeEnd 對每個 Universe::tick 進行計時
欲測量每次呼叫 Universe::tick 會花多少時間,我們可以使用 web-sys crates 中的 console.time 與 console.timeEnd。
首先,將 web-sys 加到 wasm-game-of-life/Cargo.toml 中作為相依關係。
[dependencies.web-sys]
version = "0.3"
features = [
"console",
]
由於每個 console.time 呼叫都應該有相對應的 console.timeEnd 呼叫,所以將它們封裝在 RAII 型態中會比較方便。
# #![allow(unused_variables)] #fn main() { extern crate web_sys; use web_sys::console; pub struct Timer<'a> { name: &'a str, } impl<'a> Timer<'a> { pub fn new(name: &'a str) -> Timer<'a> { console::time_with_label(name); Timer { name } } } impl<'a> Drop for Timer<'a> { fn drop(&mut self) { console::time_end_with_label(self.name); } } #}
接著,我們可以在方法的開頭加上這個程式碼片段來計時每個 Universe::tick 花了多少時間。
# #![allow(unused_variables)] #fn main() { let _timer = Timer::new("Universe::tick"); #}
呼叫 Universe::tick 一次後花了多少時間現在會記錄在主控台裡。
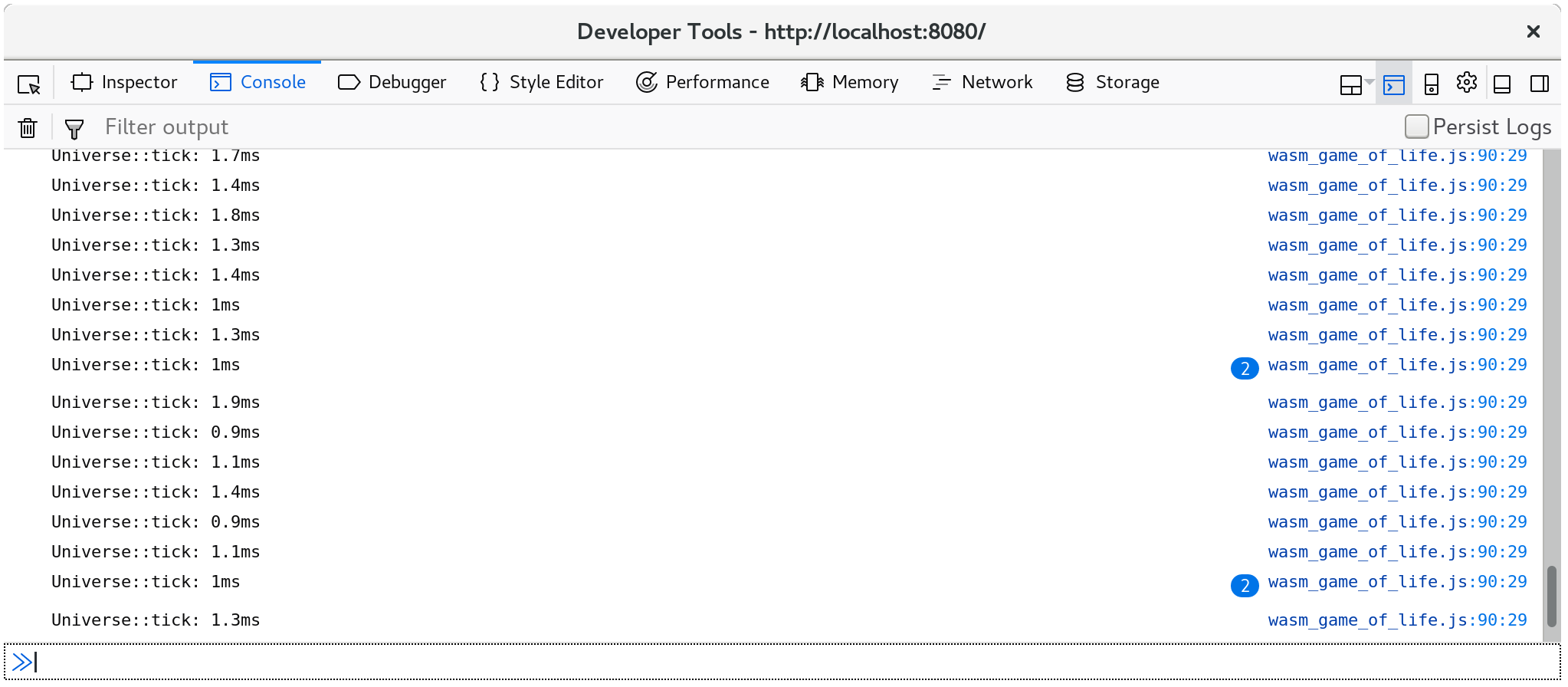
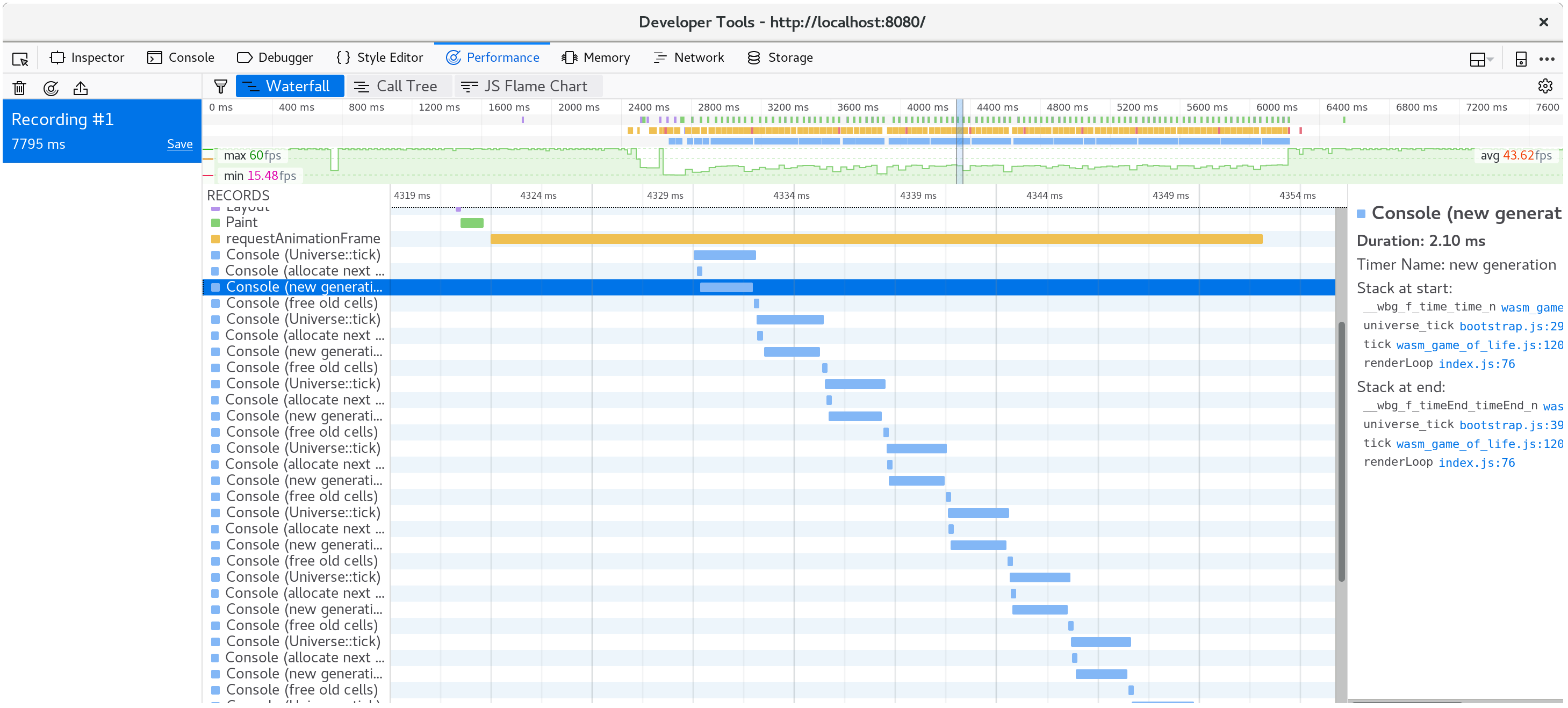
此外,console.time 與 console.timeEnd 成對組合會顯示在你瀏覽器的 profiler 的「時間軸」或「瀑布」檢視中:pp 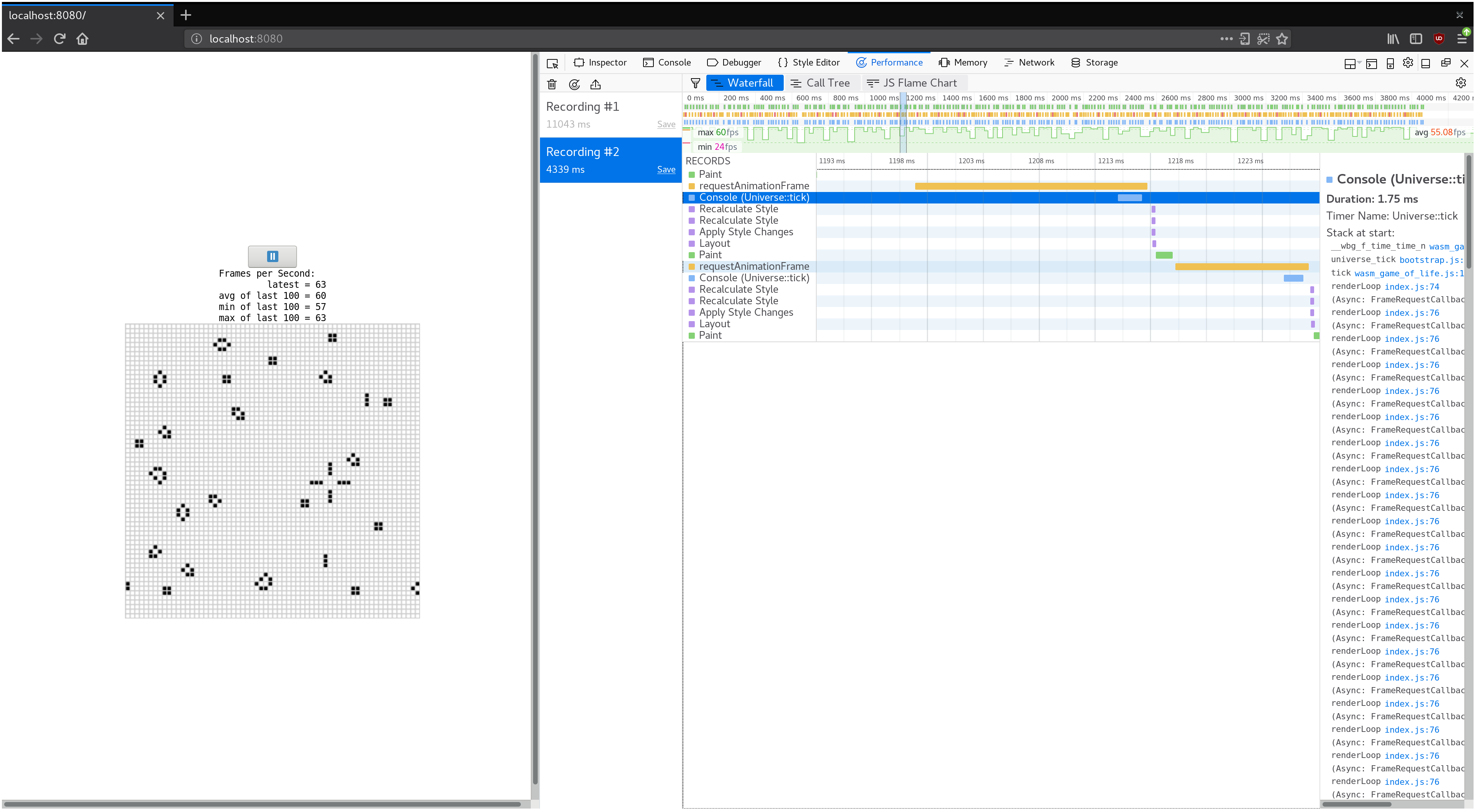
擴展我們的 Game of Life Universe
⚠️ 本節使用 Firefox 中的範例螢幕截圖。雖然所有現代瀏覽器都有類似的工具,但使用不同的開發人員工具可能會有一些細微差異。你提取的剖析資訊在實質上會相同,但你在檢視中看到的畫面和不同工具的命名可能會有些出入。
如果我們把 Game of Life universe 擴得更大會怎麼樣?將 64 x 64 宇宙替換成 128 x 128 宇宙(透過修改 wasm-game-of-life/src/lib.rs 中的 Universe::new),在我的機器上會造成 FPS 從流暢的 60 降到大約 40 的斷斷續續狀態。
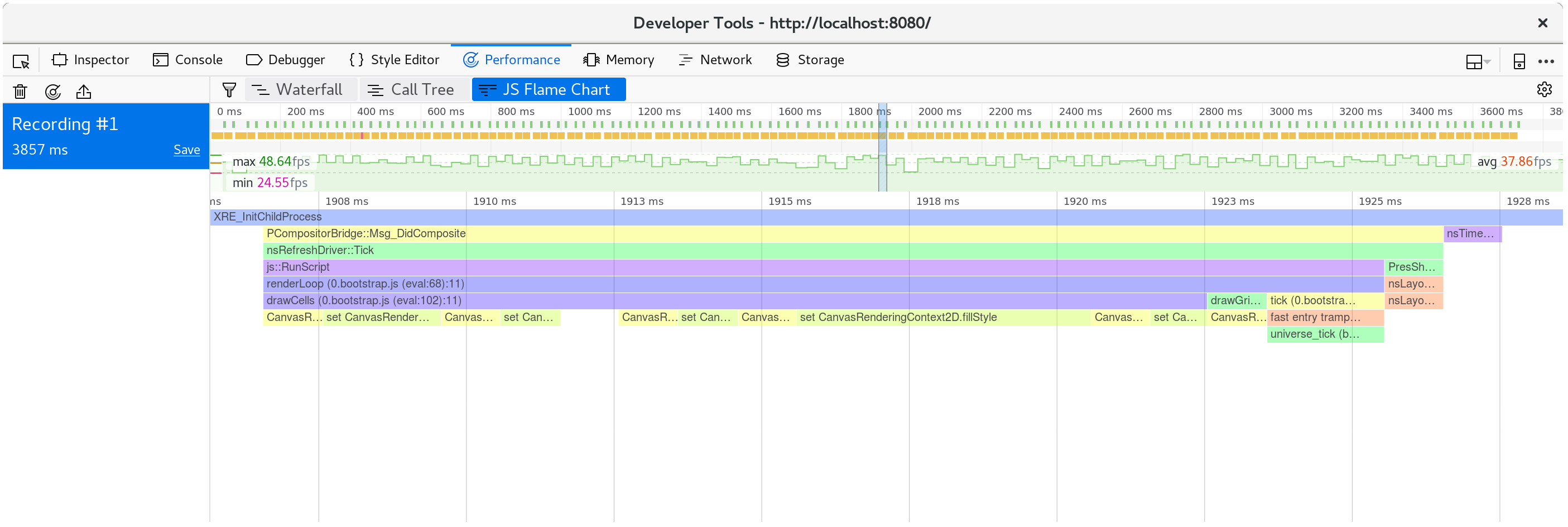
如果我們記錄剖析並檢視瀑布檢視,我們會看到每一幀動畫都花了超過 20 毫秒。回想一秒 60 幀會在整個渲染一幀的過程中留下 16 毫秒。這不只包含我們的 JavaScript 和 WebAssembly,還包含瀏覽器執行的所有其他事,例如繪製。
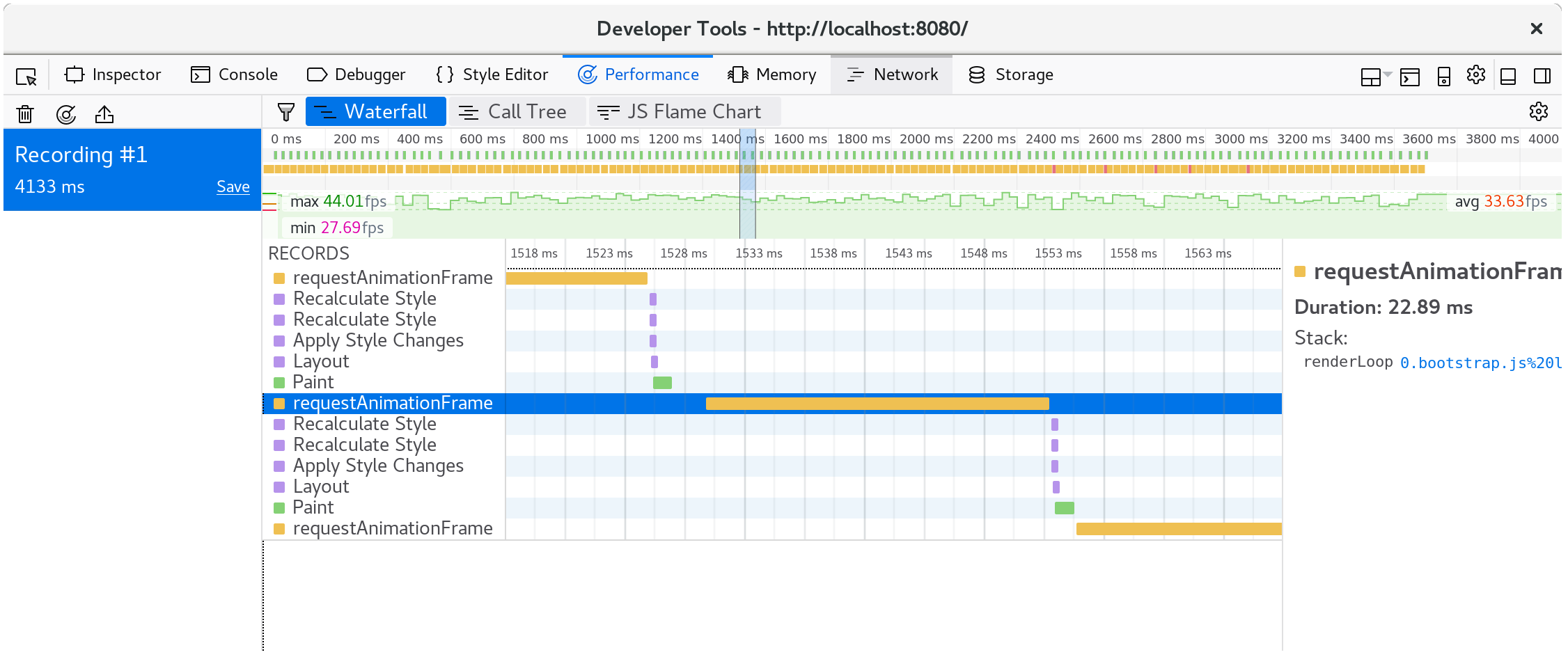
如果我們檢視在單一動畫幀中發生了什麼事,我們會看到 CanvasRenderingContext2D.fillStyle setter 非常耗費效能!
⚠️ 在 Firefox 中,如果你看到一條只顯示「DOM」而沒有提到前面所說的
CanvasRenderingContext2D.fillStyle的線,你可能需要在效能開發人員工具選項中開啟「顯示 Gecko 平台資料」選項。
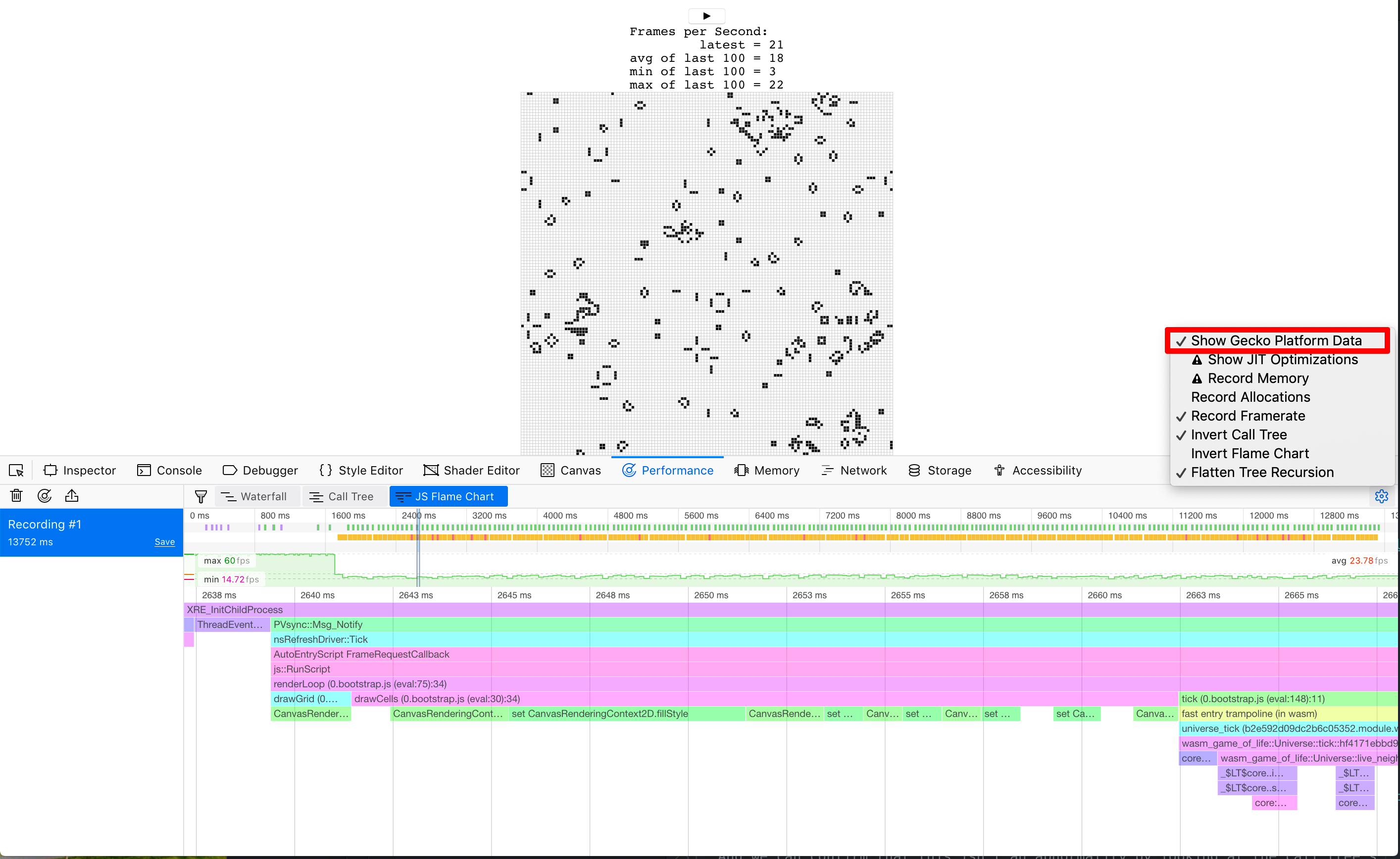
而且,我們可以檢視呼叫樹的許多幀的聚合來確認這不是異常現象。
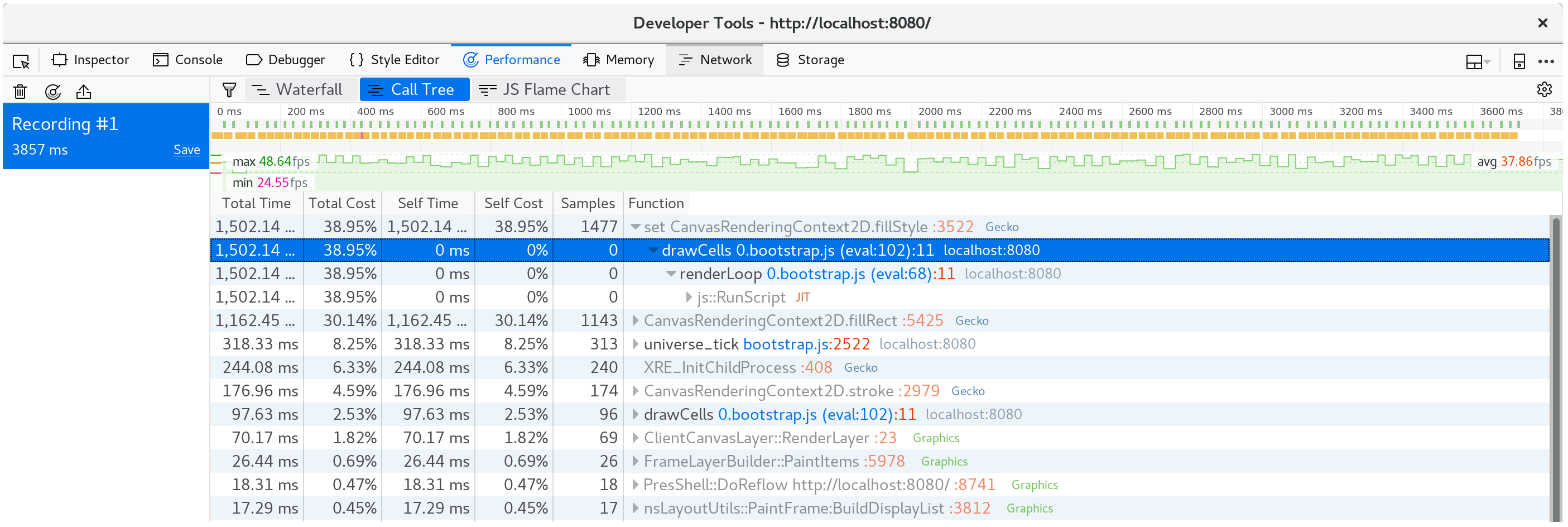
我們的時間有將近 40% 都花費在這個 setter 裡了!
⚡ 我們可能預期
tick方法中會有一些東西會是效能瓶頸,但並非如此。總是讓剖析引導你的焦點,因為花費時間的地方可能出乎你的意料。
在 wasm-game-of-life/www/index.js 中的 drawCells 函式裡,會在 universe 中的每個單元格上設定一次 fillStyle 屬性,每一幀動畫都會這樣做。
for (let row = 0; row < height; row++) {
for (let col = 0; col < width; col++) {
const idx = getIndex(row, col);
ctx.fillStyle = cells[idx] === DEAD
? DEAD_COLOR
: ALIVE_COLOR;
ctx.fillRect(
col * (CELL_SIZE + 1) + 1,
row * (CELL_SIZE + 1) + 1,
CELL_SIZE,
CELL_SIZE
);
}
}
既然我們已經找出設定 fillStyle 的運算成本這麼高,那我們可以怎麼做來減少設定的頻率呢?我們需要看儲存格是活著或死亡的,來切換 fillStyle。如果我們設定 fillStyle = ALIVE_COLOR,然後一次畫出所有活著的儲存格;接著再設定 fillStyle = DEAD_COLOR,再畫出所有死亡的儲存格,那我們就只需要設定兩次 fillStyle,而不是每個儲存格都設定一次。
// Alive cells.
ctx.fillStyle = ALIVE_COLOR;
for (let row = 0; row < height; row++) {
for (let col = 0; col < width; col++) {
const idx = getIndex(row, col);
if (cells[idx] !== Cell.Alive) {
continue;
}
ctx.fillRect(
col * (CELL_SIZE + 1) + 1,
row * (CELL_SIZE + 1) + 1,
CELL_SIZE,
CELL_SIZE
);
}
}
// Dead cells.
ctx.fillStyle = DEAD_COLOR;
for (let row = 0; row < height; row++) {
for (let col = 0; col < width; col++) {
const idx = getIndex(row, col);
if (cells[idx] !== Cell.Dead) {
continue;
}
ctx.fillRect(
col * (CELL_SIZE + 1) + 1,
row * (CELL_SIZE + 1) + 1,
CELL_SIZE,
CELL_SIZE
);
}
}
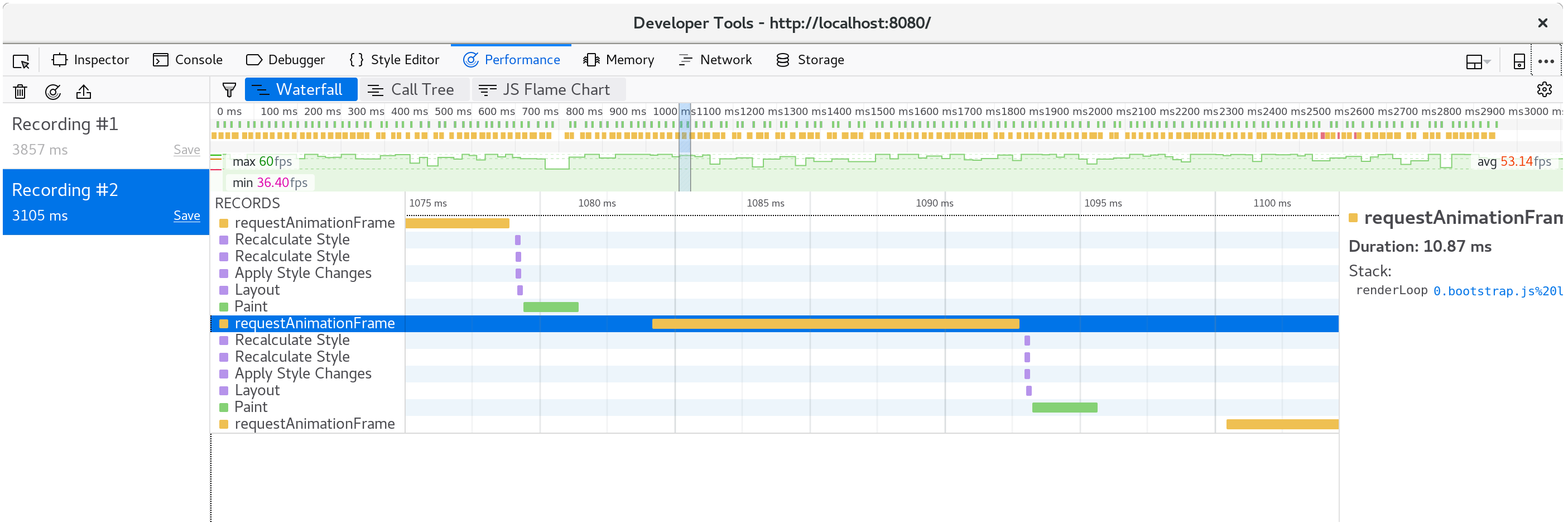
儲存這些變更後並重新整理 https://#:8080/,渲染效能就會恢復到順暢的每秒 60 幀。
如果我們再產生一個簡檔,我們可以看出現在每個動畫幀只花了大約十毫秒。
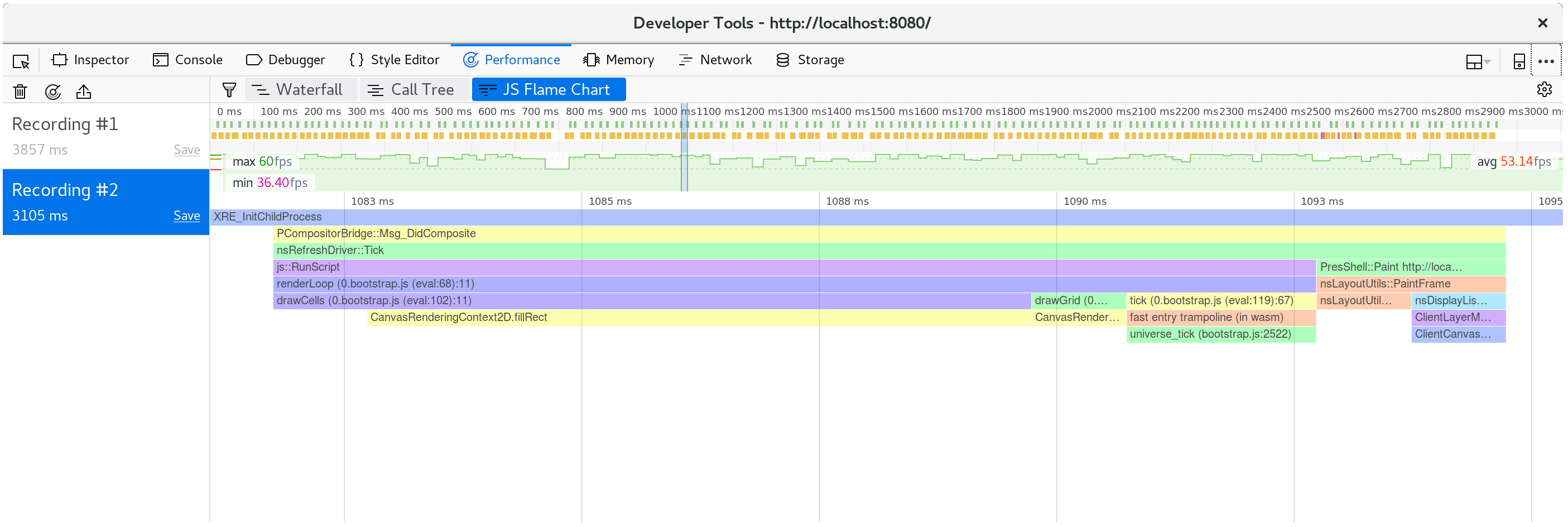
分解單一幀,我們可以看出 fillStyle 的成本已經不見了,而我們幀的大部分時間都花在 fillRect,繪製每個儲存格的矩形。
縮短時間執行
有些人不喜歡等待,他們會希望不要只在每個動畫幀產生一個宇宙的刻度,而是產生九個刻度。我們可以修改 wasm-game-of-life/www/index.js 中的 renderLoop 函式,就能輕鬆地做到
for (let i = 0; i < 9; i++) {
universe.tick();
}
在我的機器上,這讓我們回到了每秒只有 35 幀。這樣不行。我們要那順暢的 60!
現在我們知道時間會花在 Universe::tick 中,所以我們在其中加入一些 Timer 來包裝各種位元,用 console.time 和 console.timeEnd 呼叫,看看會變成怎樣。我的假設是,在每個刻度分配一個新的儲存格向量,並釋放舊的向量,這很費時,並佔用了我們大量時間。不過,這再次提醒我們要一直用簡檔來指引我們的努力!
# #![allow(unused_variables)] #fn main() { pub fn tick(&mut self) { let _timer = Timer::new("Universe::tick"); let mut next = { let _timer = Timer::new("allocate next cells"); self.cells.clone() }; { let _timer = Timer::new("new generation"); for row in 0..self.height { for col in 0..self.width { let idx = self.get_index(row, col); let cell = self.cells[idx]; let live_neighbors = self.live_neighbor_count(row, col); let next_cell = match (cell, live_neighbors) { // Rule 1: Any live cell with fewer than two live neighbours // dies, as if caused by underpopulation. (Cell::Alive, x) if x < 2 => Cell::Dead, // Rule 2: Any live cell with two or three live neighbours // lives on to the next generation. (Cell::Alive, 2) | (Cell::Alive, 3) => Cell::Alive, // Rule 3: Any live cell with more than three live // neighbours dies, as if by overpopulation. (Cell::Alive, x) if x > 3 => Cell::Dead, // Rule 4: Any dead cell with exactly three live neighbours // becomes a live cell, as if by reproduction. (Cell::Dead, 3) => Cell::Alive, // All other cells remain in the same state. (otherwise, _) => otherwise, }; next[idx] = next_cell; } } } let _timer = Timer::new("free old cells"); self.cells = next; } #}
查看計時,很明顯我的假設是錯誤的:大部分時間都花在實際計算下一個世代的儲存格上。令人驚訝的是,在每個刻度時分配和釋放一個向量,似乎成本可以忽略不計。這再次提醒我們,要一直用簡檔來指引我們的努力!
下一章節需要 nightly 編譯器。這是因為我們要使用的基準 測試功能閘門。我們會安裝的另一個工具是 cargo benchcmp。這是用來比較 cargo bench 產生的微基準的一個小型工具程式。
讓我們來寫一個本機碼 #[bench],來做我們 WebAssembly 做的事,不過這個版本我們可以用更成熟的簡檔工具。這裡是新的 wasm-game-of-life/benches/bench.rs
# #![allow(unused_variables)] #![feature(test)] #fn main() { extern crate test; extern crate wasm_game_of_life; #[bench] fn universe_ticks(b: &mut test::Bencher) { let mut universe = wasm_game_of_life::Universe::new(); b.iter(|| { universe.tick(); }); } #}
我們還必須註掉所有 #[wasm_bindgen] 註解,以及 Cargo.toml 中的 "cdylib" 位元,否則建置本機碼會失敗,並產生連結錯誤。
安裝好所有這些,我們就可以執行 cargo bench | tee before.txt 來編譯並執行我們的基準!| tee before.txt 部分會從 cargo bench 帶入輸出,並放到一個叫做 before.txt 的檔案。
$ cargo bench | tee before.txt
Finished release [optimized + debuginfo] target(s) in 0.0 secs
Running target/release/deps/wasm_game_of_life-91574dfbe2b5a124
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out
Running target/release/deps/bench-8474091a05cfa2d9
running 1 test
test universe_ticks ... bench: 664,421 ns/iter (+/- 51,926)
test result: ok. 0 passed; 0 failed; 0 ignored; 1 measured; 0 filtered out
這同時也告訴我們二進位檔案在哪裡,我們可以再次執行基準測試,但這次則在操作系統的側錄器下執行。在我的案例中,我執行的是 Linux,所以 perf 就是我要使用的側錄器
$ perf record -g target/release/deps/bench-8474091a05cfa2d9 --bench
running 1 test
test universe_ticks ... bench: 635,061 ns/iter (+/- 38,764)
test result: ok. 0 passed; 0 failed; 0 ignored; 1 measured; 0 filtered out
[ perf record: Woken up 1 times to write data ]
[ perf record: Captured and wrote 0.178 MB perf.data (2349 samples) ]
使用 perf report 載入側錄檔後顯示,所有時間都花費在 Universe::tick 上,這是預期的
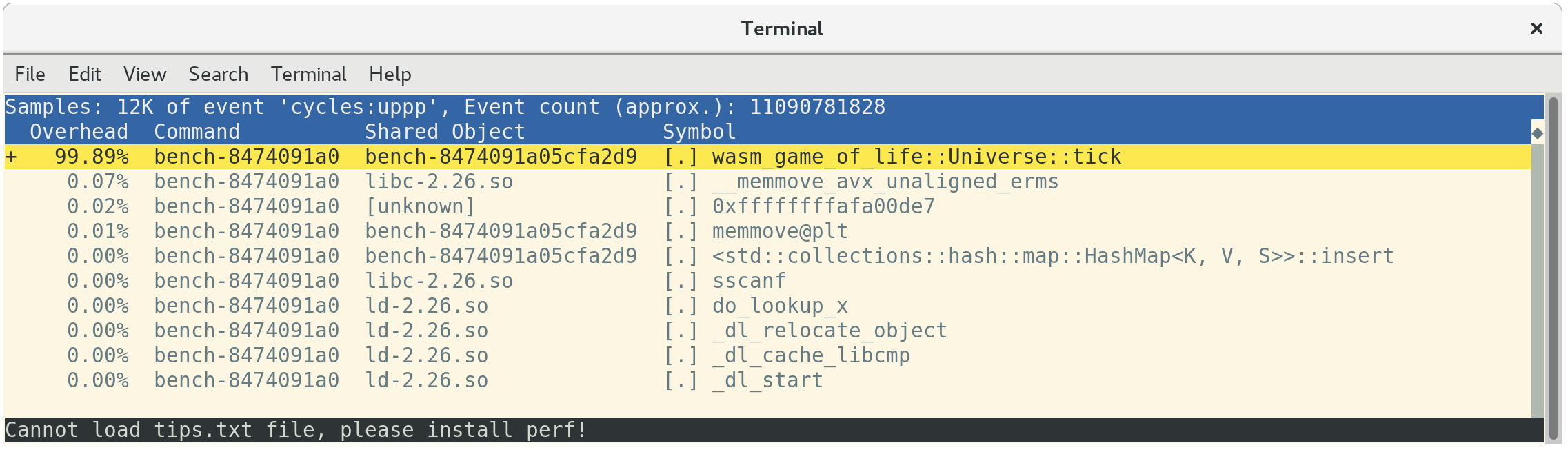
Perf 會在函式中的執行時間上標記指令,只要你按 a 鍵

這表示有 26.67% 的時間花費在計算鄰近儲存格值、23.41% 的時間花費在取得鄰近儲存格的欄位索引,以及另一個 15.42% 的時間花費在取得鄰近儲存格的列索引上。在這前三項最昂貴的指令中,第二項和第三項都是昂貴的 div 指令。這些 div 實作了 Universe::live_neighbor_count 中的模組化索引邏輯。
回想 wasm-game-of-life/src/lib.rs 中的 live_neighbor_count 定義
# #![allow(unused_variables)] #fn main() { fn live_neighbor_count(&self, row: u32, column: u32) -> u8 { let mut count = 0; for delta_row in [self.height - 1, 0, 1].iter().cloned() { for delta_col in [self.width - 1, 0, 1].iter().cloned() { if delta_row == 0 && delta_col == 0 { continue; } let neighbor_row = (row + delta_row) % self.height; let neighbor_col = (column + delta_col) % self.width; let idx = self.get_index(neighbor_row, neighbor_col); count += self.cells[idx] as u8; } } count } #}
我們之所以使用模組化,是為了避免在第一或最後一列,或欄的邊界情況下讓碼塞滿 if 分支。但即使在 row 或 column 都不位於宇宙邊緣,且不需要模組化包覆處理的最常見情況下,我們還是得支付 div 指令的費用。如果我們使用 if 語句處理邊界情況,並展開這個迴圈,則分支點 應 能被 CPU 的分支預測器預測得很正確。
讓我們重新撰寫 live_neighbor_count,如下所示
# #![allow(unused_variables)] #fn main() { fn live_neighbor_count(&self, row: u32, column: u32) -> u8 { let mut count = 0; let north = if row == 0 { self.height - 1 } else { row - 1 }; let south = if row == self.height - 1 { 0 } else { row + 1 }; let west = if column == 0 { self.width - 1 } else { column - 1 }; let east = if column == self.width - 1 { 0 } else { column + 1 }; let nw = self.get_index(north, west); count += self.cells[nw] as u8; let n = self.get_index(north, column); count += self.cells[n] as u8; let ne = self.get_index(north, east); count += self.cells[ne] as u8; let w = self.get_index(row, west); count += self.cells[w] as u8; let e = self.get_index(row, east); count += self.cells[e] as u8; let sw = self.get_index(south, west); count += self.cells[sw] as u8; let s = self.get_index(south, column); count += self.cells[s] as u8; let se = self.get_index(south, east); count += self.cells[se] as u8; count } #}
現在讓我們再次執行基準測試!這次輸出的檔案是 after.txt。
$ cargo bench | tee after.txt
Compiling wasm_game_of_life v0.1.0 (file:///home/fitzgen/wasm_game_of_life)
Finished release [optimized + debuginfo] target(s) in 0.82 secs
Running target/release/deps/wasm_game_of_life-91574dfbe2b5a124
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out
Running target/release/deps/bench-8474091a05cfa2d9
running 1 test
test universe_ticks ... bench: 87,258 ns/iter (+/- 14,632)
test result: ok. 0 passed; 0 failed; 0 ignored; 1 measured; 0 filtered out
看起來好多了!我們可以使用 benchcmp 工具和之前所建立的兩個文字檔來看出有多好
$ cargo benchcmp before.txt after.txt
name before.txt ns/iter after.txt ns/iter diff ns/iter diff % speedup
universe_ticks 664,421 87,258 -577,163 -86.87% x 7.61
哇!速度增加了 7.61 倍!
WebAssembly 蓄意地大幅近似於常見的硬體架構,但我們確實需要確認這種原生碼加速也翻譯成了 WebAssembly 的加速。
讓我們以 wasm-pack build 重新建構 .wasm 並重新整理 https://#:8080/。在我的電腦上,此頁面再次以每秒 60 個畫格執行,且使用瀏覽器的側錄器錄製另一個側錄檔會顯示每個動畫畫格約花費十毫秒。
成功了!

練習
-
在此時,加速
Universe::tick的下一個低門檻就是移除配置與釋放。實作儲存格的雙重緩衝,其中Universe維護兩個向量,從不釋放任何一個,且從不在tick中配置新的緩衝。 -
實作「建構生命」章節中的替代,增量式設計,其中 Rust 碼返回一組已變更狀態的儲存格給 JavaScript。這能讓呈現在
<canvas>中的速度變快嗎?你能在每個滴答中不配置新的增量列表下實作這種設計嗎? -
由我們的建立剖面顯示,2D
<canvas>繪製速度特別慢。將 2D Canvas 繪製程式替換為 WebGL 繪製程式。WebGL 版本有多快?在 WebGL 繪製成為瓶頸之前,宇宙的大小可以多大?